
Tic-Tac-Toe Arm Robots
The goal of this project is to simulate a robotic arm that can understands and plays the game Tic-Tac-Toe. The techniques used to accomplish this include Q-Learning (Reinforcement Learning), Python Image Processing, and a PyBullet Simulation of two robotic arms and an RGB camera.
Setup
Below describes how the simulation was setup in PyBullet:
- Two robot arms on each assigned with ‘X’ or ‘O’ on each side.
- Two trays with the cubes laid out horizontally for easy pick up.
- Five “X” cubes and five “O” cubes since the most amount of move each arm can make is five.
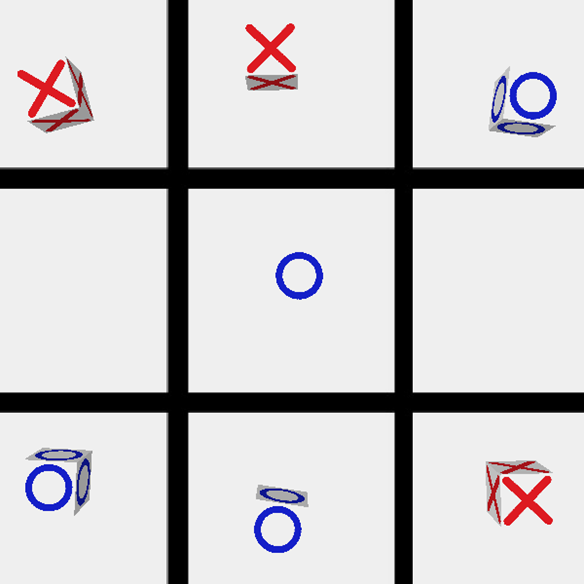
- A game board in the middle with a grid of nine boxes.
- An RGB top down camera in the middle is zoomed into the board.

Image Processing
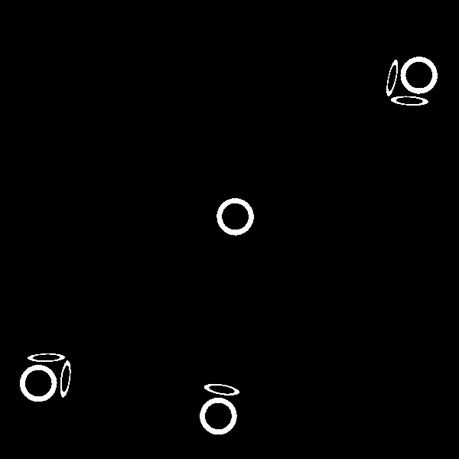
The RGB camera will capture an image of the board after every move. Image masking will then be used on the RGB image to separate the ‘X’ and the ‘O’ out into two different images. Then those two images will be scan for the positions of each cube and the result will be updated into a 2D grids of 1, -1, and 0 (which indicates ‘X’, ‘O’, and ’empty’) to be used for the reinforcement learning part.

Reinforcement Learning
In short, the robot arm will then learn how to play Tic-Tac-Toe by getting reward for winning and getting punish when losing. Using Q-learning, one robot arm will be the learning agent and start playing against an arm that places the cube randomly until it gets better. After a certain amount of iteration, the current policy will be apply onto the other arm and the learning continue on.

